论文:Rethinking the Ranks of Visual Channels
作者:Caitlyn McColeman, Fumeng Yang, Timothy F. Brady, Steven Franconeri
发表:VIS 2021 (Honorable Mention Award)
数据可以用位置、长度、亮度等视觉通道进行呈现。现有的视觉通道的排名是依据参与者能在多准确地感知到两个呈现出来的值的比值。有个假设是这个排名应该适合不同的任务以及不同数量的mark。但是,现在很少有工作对这个假设进行验证,特别是在现实世界的可视化任务中,计算比值computing ratios比观察/记住/比较趋势和主题显得不那么重要,因为目前的可视化通常呈现超过两个数据值。
为了模拟用户粗看一眼可视化后得到的信息,我们要求参与者立即根据记忆复现刚刚展示的可视化。这个数据值可以通过position(bar), position(line), luminance, area, length, angle展示。通过一个贝叶斯层级模型,我们展示了在不同数量的mark(2/4/8)下视觉通道排名的变化,以及bias, precision, error measures的转变。即使重现2个marks,排名也不一致;对于不同数量的mark,新的排名也很不一致。除了视觉通道的选择,其他因素对排名的影响要大得多,比如数据数量(e.g. 更多的marks会导致更多的error),或者是每个mark的数值(e.g. 小的数值通常被高估)。每个视觉通道在8个marks的显示呈现效果会比4个差,这和既定的视觉记忆的限制是符合的。
这些结果表明需要一系列实证研究,不仅仅把二值比判断(two-value ratio judgments)作为对视觉通道质量进行可靠排序的baseline,包括测试新任务(趋势或主题的检测)、时间尺度(立即计算、 或稍后比较),以及数据的数量(从少数到几千)。
背景介绍
创作可视化的时候,设计者需要选择合适的视觉通道展示数据,其中一个主要的制约因素是该通道的感知精度。而视觉通道的排名是由专家判断或者由特定的任务得出的。最值得参考的是二值比判断的感知精度。比如用positon来编码,用户可能估计A是B的85%,这和真实的答案80%比较接近。如果用length编码,错误率会比position高。用luminance编码,虽然我们不知道如何衡量亮度通道的比值判断误差,但专家判断这个误差会很高。
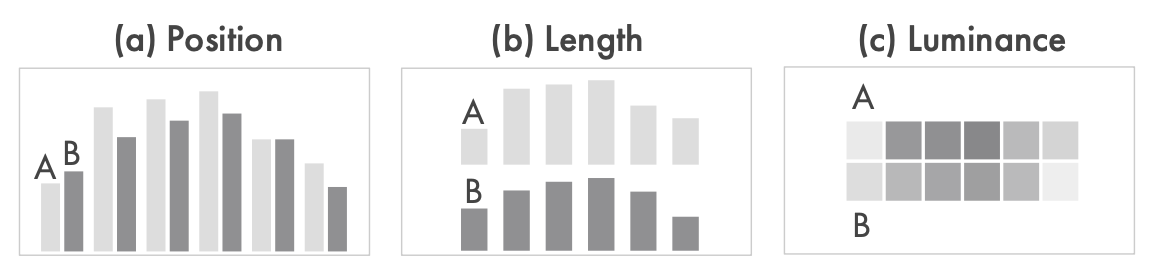
我们把现有的视觉通道排名(从二值比判断的误差测量中得出的)作为决定如何呈现数据的关键因素,隐含着一个假设—它应该广泛地延伸到观众在真实世界的可视化和视觉分析中执行的低级别的视觉任务类型。但这样的假设过于大胆,因为可视化通常需要我们在远超两个值之间提取,记忆,比较统计数据、趋势和主题,导致现有的排名不可靠。在分析数据时的十个低层次感知任务中,计算比率并不是其中一种,但检索值的任务是存在的,而且这个任务是图表的二值比率判断的基础。
retrive value, filter, compute derived value, find extremum, sort, determine range, characterize distribution, find anomalies, cluster, correlate
在上图中,A/B中最高/最低的三个值是什么?每队的最大差异在哪里?…有很多这样的比较任务,涉及到多个数据值,而目前没有工作来评估现有的排名通道是否适用于它们。
比较任务要求在视觉记忆中保留一组数值,并将记忆和随后感知的数值进行比较。至少,不在视距内的比较,需要眼球运动或翻页,肯定需要视觉记忆,而且收到容量限制。记得信息越多,精确度会急剧下降,偏差会上升,容量也会达到上限。所以在论文实验中,我们把数据值的数量当作一个变量。
本次研究使用复现任务,但没有假设这种测量方法可以推广到各种比较任务。这可以让我们初步了解视觉通道和标记的数量是如何影响复现性能的,而不需要对各种类型的视觉比较进行更具体的操作。
我们要求参与者立即复现刚刚在六个通道和三个标记数量「2,4,8」上看到的一组数值。我们的贝叶斯层级模型的结果显示,现有的排名并不成立,即使是复现2个标记。新的概率排名也随着标记的数量变化而变化。除了通道的选择,其他的因素对性能的影响要大一个数量级,比如标记数量、每个标记的值。在每个视觉通道中,当需要存储记忆的标记超过一定数量的时候,性能也会急剧下降,这和已知的视觉记忆的限制🚫是一致的。
贡献点
- 实验研究结果
- 六个编码的视觉通道以及标记数量「2,4,8」对复现一组可视化数据的影响,导致了对现有排名(基于二值比任务)的重新评估;
- 基于上下文的概率排名
- bias, precision, error;
- 公开数据集
- 28602份测量复现性能的数据集,以及描述该数据集的贝叶斯层级模型;osf;
相关工作
视觉判断的语境和偏见影响
Cleveland和McGill测试了只有两个相关值的判断本身的比率判断的精确性,但他们也显示了这些值被添加到其他值后,显示的精确性下降。最近的工作发现了类似的精确度下降现象。在其他复现任务中,就像本研究中使用的任务一样,显示的周围数值产生了记忆偏差,例如,对单个相关数值的回忆被排斥在第二个较大的参考条的0、0.5和1.0比例之外。即使是单独呈现的数值,也出现了记忆偏差,如高度:宽度比高的高条被低估,而高度:宽度比低的宽条被高估。
除了二值比较的评估方法
有研究对可视通道的相关性判断的精度进行了排序,基于位置的散点图精度最高,但基于位置的线图精度最低;角度,在二值比任务中具有最低的精度的通道,却在这个任务中显示了第二高的精确度。尽管在这种情况下,相关性判断不是由角度本身提取的,而是由角度创造的高负相关的形状提取的。
当判断平均或分布的聚合属性时,排名可能会逆转。典型的低排名通道-亮度-可以在这些任务中表现最佳。对极值或范围的判断,位置通道的可视化依然表现最佳。另一项任务的研究任务是:读取数值,比较数值,找到最大值,比较平均值。使用了位置、大小、颜色的通道的可视化,研究发现,提取单一值时位置是最快速和准确的;但是对于平均数这样的聚合属性,颜色显示了相同的性能。另一项研究发现,柱状图在寻找值的集群方面有优势。散点图在异常检测方面有优势,但不适合集群检测。
还有研究评估了两个任务之间的视觉通道的比较,比如在上图中左侧的柱状图中找到两个成对的数值之间的最大差异。实验包括了柱状图,折线图和甜甜圈图,比较每种图表类型中的数值排列。不同图表类型之间方法的不同使得这种比较很困难。
本次研究依赖于一个单一的任务——复现,更具有概括能力。
视觉记忆
每次只涉及1或2个项目的任务的记忆表现情况可能无法预测更复杂的视觉显示的情况。增加记忆值的数量将导致难以预测的性能变化。由于几乎所有的数据可视化都包括1或2个以上的标记,所以直接研究这些情况而不是假设从1或2个标记的研究中得出的教训会普遍适用于这些更大的值集是至关重要的。
在本研究中,参与者被要求复现2/4/8个标记的可视化,以收集来自不同质量的记忆负荷的数据。参与者依靠的是数据值的复现,而不是对可视化的主要信息的语义回忆或他们以前是否遇到过整个图像。这项任务是典型的视觉工作记忆任务的一个类比,作为一个代理,它代表了一个人如何在眼球运动和延迟中保留标记的值(如在阅读与可视化相关的文本时)。
实验方法
可视通道
6个-涵盖大部分排名中的通道by Cleveland and McGill:position (bar) (bar chart), position (line) (line chart), luminance (heatmap), area (bubble chart), length (misaligned bar chart), and angle (wind map).
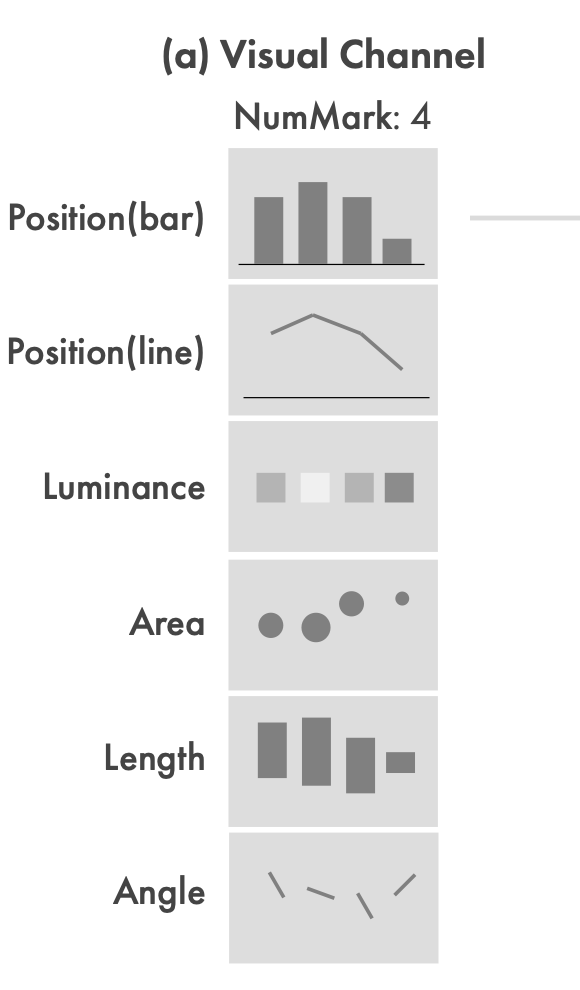
标记数量
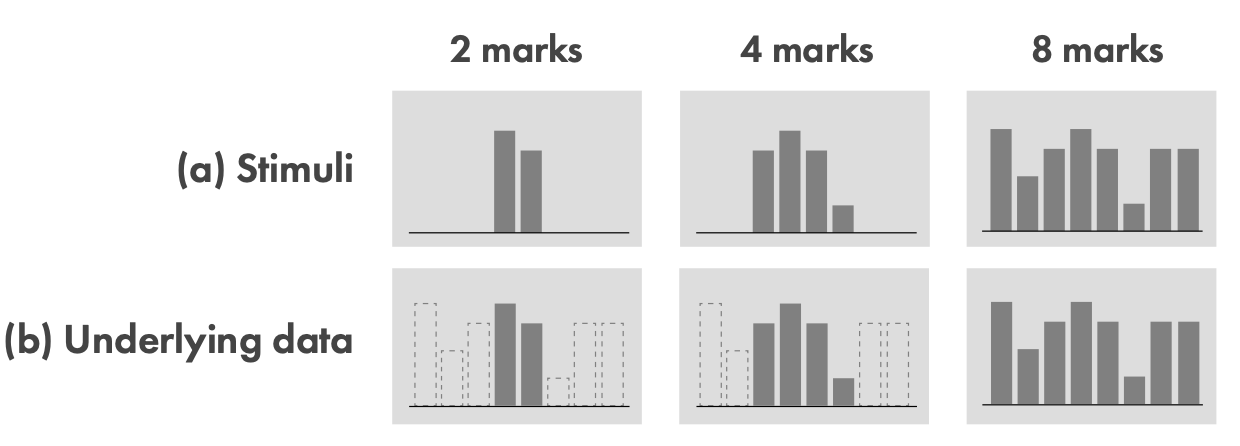
2/4/8;用户必须重新绘制可视化而不是指出比率;以此推断记忆的限制如何影响复现;
实验设计
6个视觉通道分为两组,并保持实验时间在30min左右;
一组测试position (bar), position (line), and luminance;每个VisualChannel x NumMark13次trials;
另一组测试length, area, and angle;每个VisualChannel x NumMark15次trials;
生成Stimuli
数值范围[0.01, 1.0];背景rgb(0.75, 0.75, 0.75);对6个通道的范围分别做了规定;
所有数据预先生成8个,只是显示的数量不同;随机均匀采样{0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0};
实验流程
常规流程:知情同意书 — 实验说明 — 现场培训并解答问题
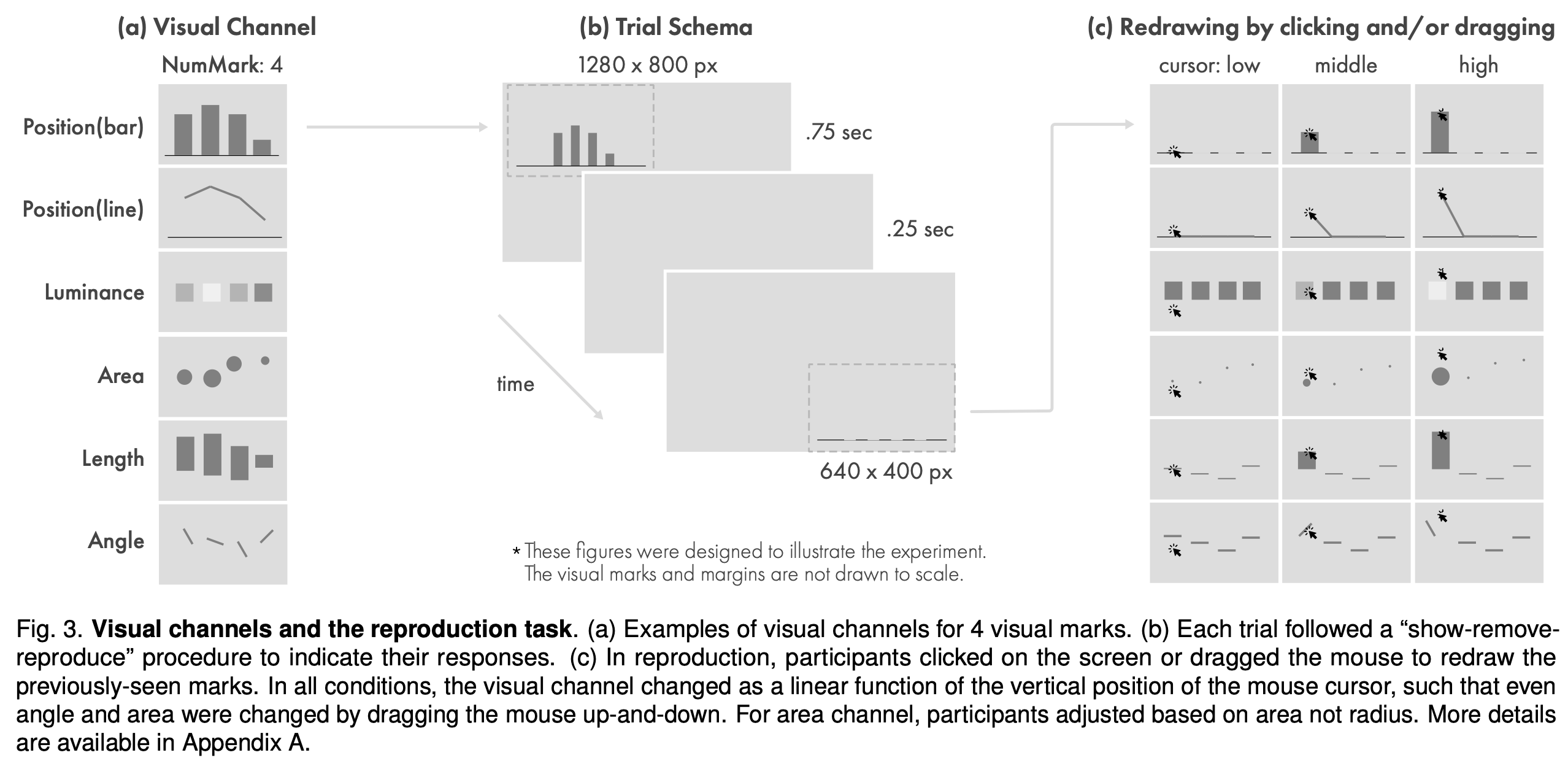
参与者: 两次实验分别招募了30名和29名参与者。他们是同一所大学的本科生,参加了心理学的入门课程,他们以自己的时间来换取部分学分。受试者年龄在18至23岁之间(μ=19.02岁,σ=0.96;22名女性,34名男性,3名未说明),都有正常或矫正后的正常视力。同一作者和实验者监督了所有的实验环节,并在COVID-19大流行之前完成了这些实验。
仪器: 使用Psy- chophysics工具箱和MATLAB 2018a实现,在Mac Mini(OS 10.10.5)上运行。显示在一台23英寸的显示器上,分辨率设置为1280×800像素,刷新率为60赫兹。参与者坐在离显示器大约18.5英寸的地方。
数据收集
排除了特殊情况,一个是疲劳实验排除,一个是角度上180/0的混淆;
收集的数据包括:the reproduced value of each mark, the order of visual marks, the reference values shown on the screen, the reaction time, VisualChannel, NumMark, and the trial index;
6129 trials = 3 VisualChannels × 3 NumMarks × (13 trials × 27 participants + 15 trials × 22 participants).;
28,602 responses = 3 VisualChannels × (2 + 4 + 8) marks × (13 trials × 27 participants+ 15 trials × 22 participants).
实验分析
度量
真实值-the reference;以下是反应的同一分布的不同面的度量;
bias
responses的平均值和reference的偏离;系统性错误或在某一方向上犯错的倾向,比如高估宽柱子的bias;
precision
参与者responses的一致性;可能会持续相同的数值,而不管参考值是多少;
error
每个response和reference的偏离;
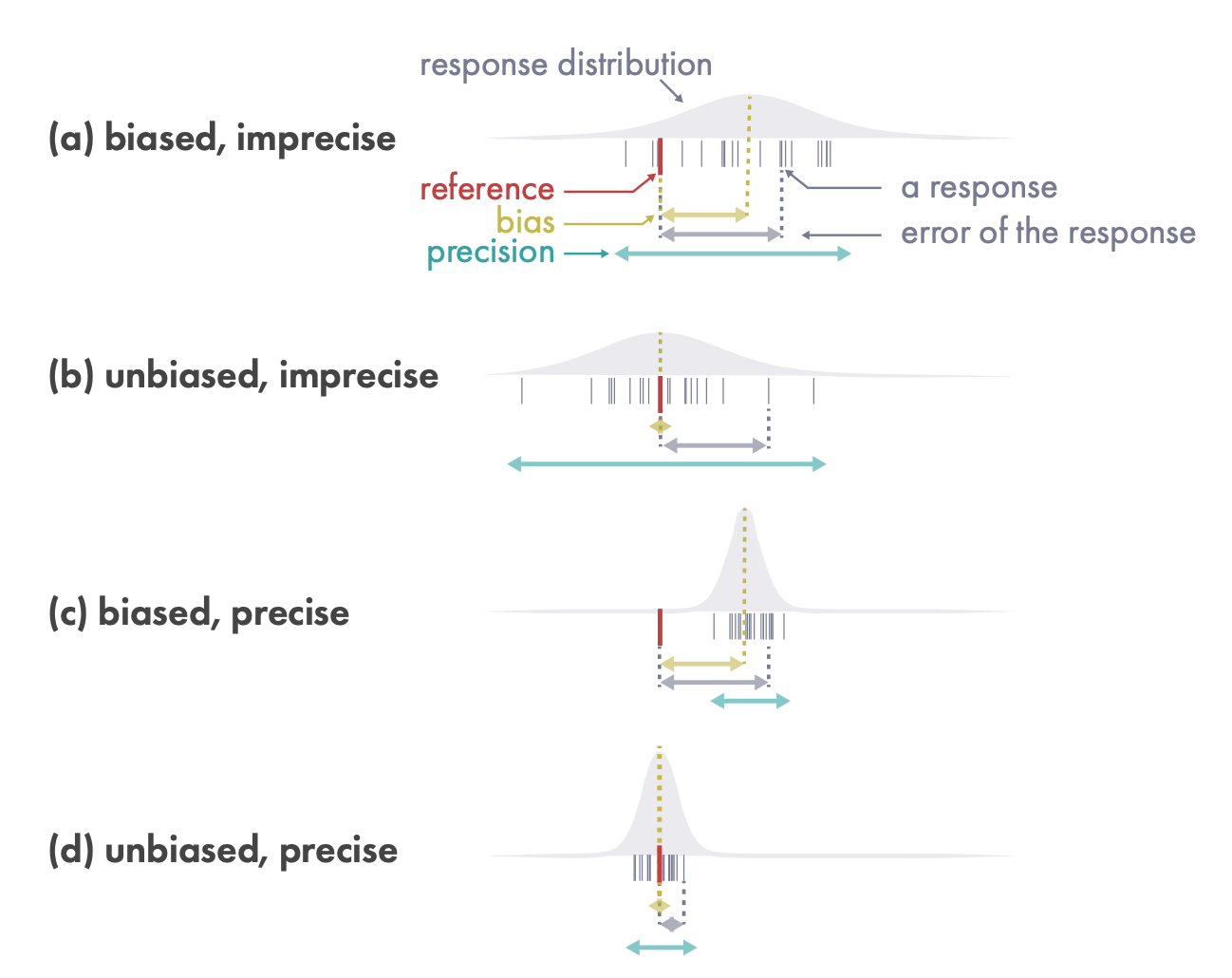
Bias和precision描述了一组反应的平均属性(例如,来自一个或多个实验条件、一个或多个参与者的反应);
Error是对单一反应的测量,结合了bias和precision;它具有更多的不确定性;
这三种测量方法中的每一种都与reference有关,在本文的其余部分,我们从每个反应中减去reference,并将所有的原始反应转化为误差(即,相对反应=原始反应-参考值);
贝叶斯层级模型
模型迭代
- 从一个最小的模型开始,这个模型只包含实验变量和一个潜在的预测因子列表,按照它们在我们主观信念中的重要性排序;
- 逐步增加预测因子,并通过检查其后验预测和系数的后验分布来评估每个中间模型;
- 我们使用WAIC(广泛适用的信息准则)和LOO(离开一出交叉验证)来比较每个中间模型和最后一个模型的样本外预测准确性,并检查它们的Akaike权重(这些预测中差异的概率);
- 也从弱信息性的预设开始,并随着模型的扩展逐渐规范化预设;
- 选择了在解决我们的研究问题、描述当前数据和预测未来观察结果方面最好的最终模型。
最终模型
具体解释不在博客中展开;

实验结论
为了了解复现任务的视觉通道的差异,整理了对bias、precision和error measurements的各种影响。由此推导出视觉通道的排名;
我们的推断基于混合模型的第一分布和后验分布(边际分布、条件分布和预测分布)。边际后验分布总结了一个参数的所有已知信息;条件后验分布告诉我们一个参数在特定情况下的预期值;后验预测分布提供了对观察数据和拟合模型的未观察数据的调节。
主要影响
模型表明,两个实验变量—标记数量(NumMark)和参考值(ReferenceValue)—都对三种度量有非常大的影响。为了显示这些影响,我们取一个平均参与者(以消除个体差异),以median trial为条件(摆脱学习/疲劳效应),以及在数据平均值等于参考值的情况下(以消除同一试验中其他标记的影响)。
bias
标记数量—当标记的数量较少时,平均参与者在复现中的偏差非常可能较小。对于一个平均的视觉通道和一个平均的参考值,平均参与者在有2个标记的图表中比有8个标记的图表中的偏差要小的估计概率是0.92。也就是说,对于相同的参考值,我们期望92%的带2个标记的回答比带8个标记的回答表现出更少的偏差。
参考值—一般被试者很可能高估小的参考值,严重低估大的参考值,而在参考值为0.4或0.5(中位数)左右时,被试者的偏差最小。对于一个平均的视觉通道和平均的标记数量,被试者在参考值中位数(.5)的图表中比最小值(.1)的偏差小的估计概率是0.93。同样,在参考值中位数(.5)的图表中,平均参与者比最大值(1.0)的偏差小的估计概率是0.93。
互相影响—NumMark和ReferenceValue的影响是相互作用的,它们各自与VisualChannel相互作用。对于大多数视觉通道来说,除了位置(线)之外,当标记的数量较多且参考值偏离中位数较多时,反应偏差会增加。总的来说,角度是响应偏差对标记数量或参考值的变化最敏感的视觉通道;位置(线)是偏差对参考值敏感的地方,但对大参考值的标记数量是稳健的。
precision
标记数量—当标记的数量较少时,一般被试者很可能更精确(更一致)。对于一个平均的视觉通道和一个平均的参考值,被试者用2个标记的图表比用8个标记的图表更精确的估计概率是0.99。
参考值—一般被试在复现小参考值时更精确,而在复现大参考值时则更不精确。对于一个平均的视觉通道和平均的标记数量,被试者对最小参考值(.1)比中位数或最大参考值(.5或1.0)更精确的估计概率是1.00(几乎是确定性的)。
互相影响—这两个变量对精确度的影响是相互影响的,并进一步与视觉通道相联系。当参考值较小时,反应精度受标记数量的影响较大,但角度除外,当参考值较大时,精度受标记数量的影响较大。同样,除角度外,参考值越小,精确度越受参考值的影响,而参考值越大,精确度越受影响。总的来说,亮度是精度对参考值最不敏感的视觉通道,而位置(线)是精度对参考值最敏感的地方。
error of individual response
从后验分布中抽取的样本提供了个别反应的误差;为了方便比较采取了绝对值。
标记数量—一般的参与者可能会在较少的分数下出现较小的错误。对于一个平均的视觉通道和一个平均的参考值,一个未来的反应在2分的情况下表现出比8分更小的错误的概率是0.71。
参考值—一般参与者在参考值较小的情况下可能会出现较小的错误。未来单个响应的最小参考值(.1)的误差比最大参考值(1.0)小的估计概率是0.74。
互相影响— 在面积和角度的参考值较大的情况下,复现误差可能受标记数量的影响略大,在位置(条)和位置(线)方面则较小,而在亮度和长度的不同参考值方面也是如此。这些相互作用的影响比观察到的偏差和精确度的影响要小,部分原因是相对于偏差和精确度所描述的综合属性而言,这种测量方法的不确定性增加了。
次要影响
以参考值和相关数据平均值都在中位数(分别为0.5,0.55)的平均情况为条件,并对数据平均值的所有可能值进行抽样;将标记和视觉通道的数量边际化,并使用一个平均参与者。
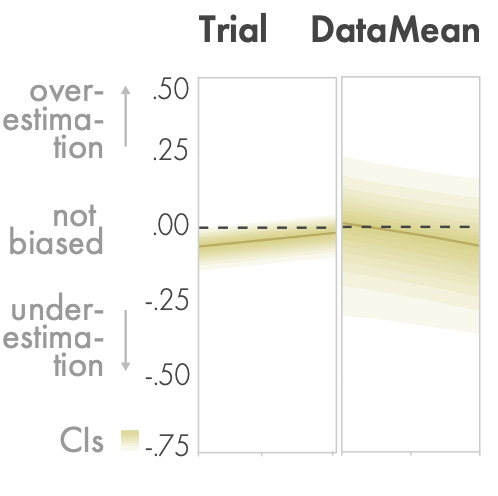
bias
在实验开始时,被试者似乎低估了参考值。在后来的试验中,被试者一般会增加复现的数值,变得不那么偏颇。在复现平均值时,被试似乎不受其他小参考值的影响,但当其他参考值较大时,被试可能会低估中值。
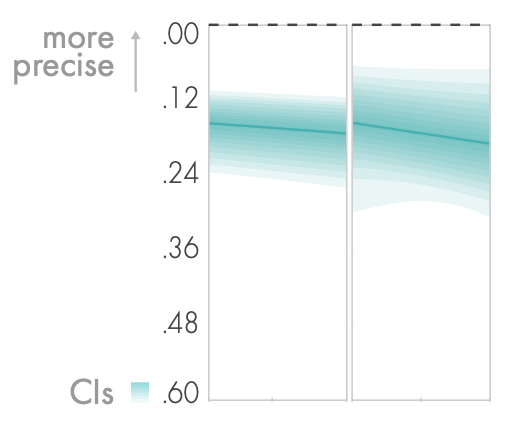
precision
随着实验的进行,参与者似乎变得稍微不那么精确,可能是由于疲劳效应。在复现一个平均值时,当同一试验中出现其他较大的数值时,被试似乎不那么精确;这些较大的数值可能分散了被试的判断力和复现。
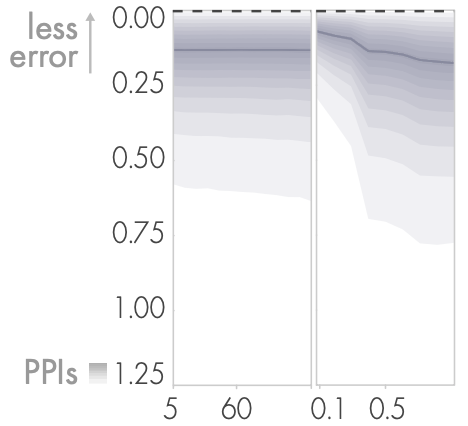
Error of individual response
学习或疲劳效应对反应错误的影响并不强烈。在复现一个平均值时,当其他参考值较小时,被试可能会出现较小的错误,而当其他值较大时,则会出现较大的错误。当数据平均值高于0.25,即中位数的一半时,反应的误差似乎会大大增加。
概率排名
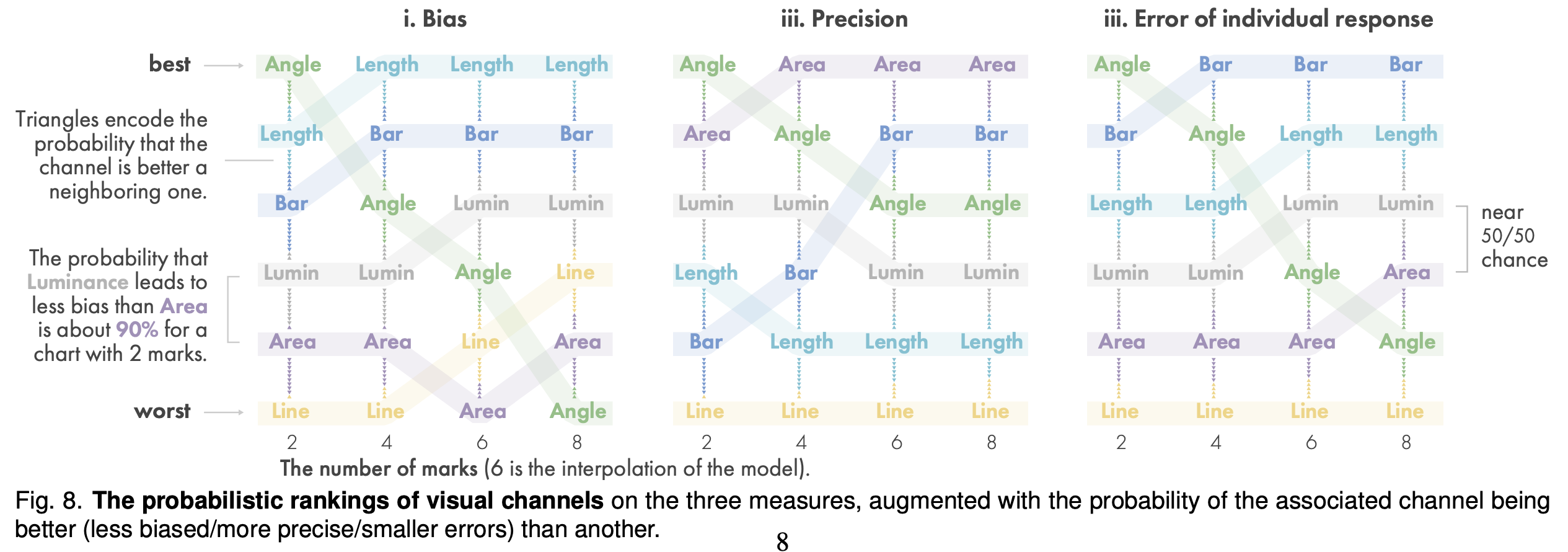
讨论与总结
讨论
context
- 对每个值的记忆可能也取决于它与其他值的分布的关系;
- 一个标记的值(参考值)对复现的影响比所选择的渠道更强大;
- 参考值的上下文也表明了强烈的偏见;
implications
- 设计者应该越来越怀疑双值比任务所产生的视觉通道排名,这可能不能作为其使用的通用准则;
- 视觉通道以外的其他因素可能是设计建议的关键;
- 将数据属性(标记的数量、数值)的影响参数化,以及设计者对低偏差、高精确度或低误差的优化愿望,可能有助于为可视化设计者的决策提供信息;
- 文章的建模方法可以协调不同的因素并提供设计候选方案;
- 在本研究的基础上推导出其他坚定的准则还为时过早;还需要更多的研究或确定是否存在广泛适用的准则。
limitations
- 我们在设计实验和分析数据时对所有的视觉通道都一视同仁。这更容易比较,但对某些人来说可能是以牺牲可用性为代价的。
- 重新绘制的方法可能会增加数据的噪音和偏差,因为它对所有的视觉通道可能不是同样直观的。
- 该模型还始终假定反应的误差与所有变量之间是线性的。虽然大多数数据符合这一假设,但像角度这样的视觉变化在不同的参考值中显示出适度的非线性,可能会影响模型的估计。
总结
重新审视了视觉通道的排名,使用复现任务作为各种视觉比较任务的代理。我们测试了参与者对六个视觉通道的复现表现:位置(条)、位置(线)、亮度、面积、长度和角度,在不同的标记数量和数据值下。
通过贝叶斯多层次模型发现标记的数量和参考值都会强烈影响一组反应的偏差和精度,以及单个反应的错误;标记的数量逐渐主导了视觉通道和参考值的差异,反映了对工作记忆的强烈限制,这可能会限制数据可视化的大多数比较任务。我们进一步从模型中推导出每个措施的概率排名,并表明之前的排名并不成立。
提供了基于再现任务的初步的新排名,并提出了一种贝叶斯建模方法来对视觉通道进行排名。
✉️ zjuvis@cad.zju.edu.cn